这篇文章介绍大语言模型的一些概念,包括它是如何工作的,什么是Token等等。
大语言模型如何工作
我们从一个示例开始说起。
当我们写一个提示“我喜欢吃”,然后要求一个大型语言模型根据这个提示填写后面可能的内容。它可能会说,“带奶油奶酪的百吉饼,或者我妈妈做的菜”。
但是这个模型是如何学会做到这一点的呢?
1 | %env OPENAI_API_KEY=sk-XXX |
获取openai开放的模型列表:
1 | import openai |
大型语言模型的一个令人兴奋的方面是,你可以利用它来构建一个定制的聊天机器人,并且只需付出少量的努力。ChatGPT 的网页界面可以让你与一个大型语言模型进行对话。但其中一个很酷的功能是,你也可以利用大型语言模型构建你自己的定制聊天机器人,例如扮演一个人工智能客服代理或餐厅的人工智能点餐员的角色。本篇文章将揭晓如何做到这一点。
下面是两种调用OpenAI接口的函数。get_completion只支持单轮对话,意味着模型回答问题时不会考虑之前的对话信息。get_completion_from_messages支持多轮对话信息。这是因为它的参数message可以包含对话的上下文。下面我们看看它们在对话机器人中是怎么使用的。
最近debug程序真是越来越离不开ChatGPT了。将问题直接抛给ChatGPT大大提高了我查找问题的速度。很多时候我已经无需另外使用搜索引擎来查找资料了。
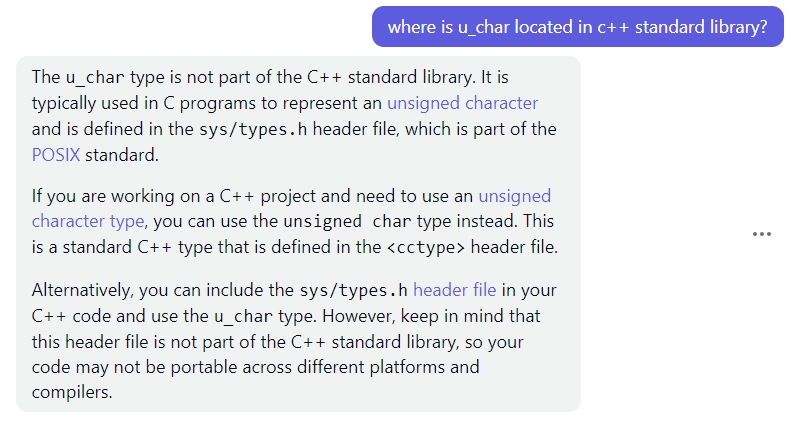
这个是我将一段Linux上运行的程序移植到Windows上运行时出现的问题。编译发现没有u_char这个类型。开始我以为是Linux和Windows上标准库不一致。向ChatGPT请教了一下,它直接告诉我这个类型是Linux的系统文件定义的。简单快速地解决了我的疑惑。
现在是信息爆炸时代,打开手机,各种文章扑面而来。我们的精力是有限的。如果有人帮忙把文章总结好给我们,这不就节省了很多时间嘛!我们也就可以阅读更多的文章了。
恰好大语言模型在总结文章方面非常有天赋。
这节介绍大模型判断文字的语义,或者说对内容进行情感分析的能力。同时也演示了大模型如何提取出文字中的关键信息。
在传统的机器学习方案中,要做到对文字内容的情感分析,需要先对一系列的文字内容(如评论)进行人工标注。把这些文字内容人工分类成“正向”和负向“,然后再喂给一个机器学习模型去训练,得到一组参数。模型训练好后再部署好,把需要判断的未标注文字内容给到训练好的模型,让它判断一下文字内容的情感倾向。
可以看到,对于传统的机器学习方案,有很多工作需要做。而且这个训练出来的模型也只能干这一件事情。如果我们想要提取文字内容中的关键信息又得重新训练另外一个单独的模型。
文字扩展是将较短的文本片段,例如一组指令或主题列表,交给大型语言模型生成更长的文本,例如基于已有的内容生成一封电子邮件或一篇关于某个主题的文章的任务。又或者你列出大纲,标题,让大模型填充对应的内容。
另外,还有一些很好的用途,例如将大型语言模型用作头脑风暴的伙伴。
但这里必须要提醒的是,ChatGPT生成的内容不一定准确,所以使用的时候要认真甄别。比如著名的stack overflow网站就曾被chatgpt的回答霸占,导致网站上充斥着不准确的回答。官方随即封禁了ChatGPT。
下面是调用openai的completion接口的函数。但在本文中并不是重点。了解一下就好。
1 | import openai |
下面我们来说说,书写提示词的基本原则。